#44 Delta Lake Usage in Microsoft Fabric: The Foundation of a Reliable Lakehouse
/ 6 min read
Updated:TL;DR
-
What it is: Delta Lake is a storage layer that adds the reliability of a database (like ACID transactions) to your cheap, scalable cloud data lake storage (like ADLS Gen2 or S3). It turns your “data swamp” into a reliable “Lakehouse.”
-
How it works: It adds a transaction log (
_delta_log) to your data files. This log tracks every change, making operations safe and enabling powerful features. -
Key Features:
- ACID Transactions: Prevents data corruption from failed jobs or concurrent writes.
- Time Travel: Query or restore previous versions of your data.
- Schema Enforcement: Stops bad data from being written to your tables.
- Unifies Batch & Streaming: Use the same table for both.
-
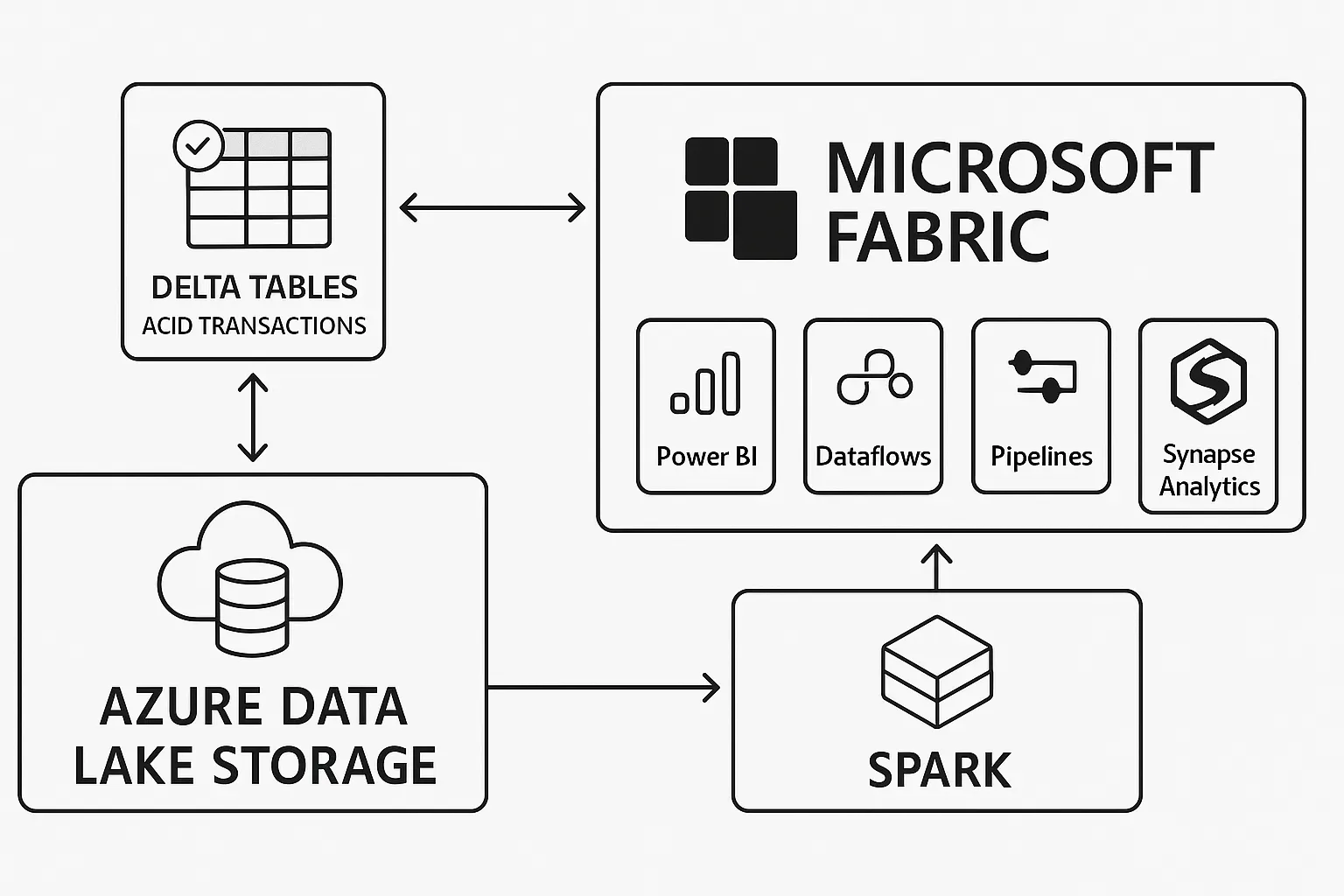
In Microsoft Fabric: Delta Lake is the default, foundational format for everything in OneLake. This is what allows different engines (Spark, SQL, Power BI) to work on the exact same copy of data without moving it, ensuring consistency and speed.
-
When to use it: Use a traditional database for applications. Use Delta Lake to build a large-scale, cost-effective, and reliable “single source of truth” for all your raw, streaming, and transformed analytical data.
The Bedrock of the Modern Data Platform: Why Delta Lake is More Than Just a File Format
For years, a chasm existed in the data world. On one side stood the data warehouse: structured, reliable, and powerful for business intelligence, but expensive and rigid. On the other was the data lake: a vast, cost-effective repository for raw data in any format, but notoriously unreliable and often devolving into an unmanageable “data swamp.”
We tried to bridge this gap with complex ETL (Extract, Transform, Load) pipelines, constantly shuttling data back and forth. But what if we didn’t have to? What if we could give the flexible, affordable data lake the intelligence and reliability of a warehouse?
That is the promise of Delta Lake, and it has become the foundational storage layer for modern data platforms like Microsoft Fabric for a reason. It’s not just an incremental improvement; it’s the architectural shift that makes the “Lakehouse” concept a reality.
The Problem: A Lake Full of Broken Promises
A traditional data lake, built on cloud storage like Azure Data Lake Storage or Amazon S3, is great for storing files. But when you try to treat it like a database, things fall apart:
- Failed jobs corrupt data. If a Spark job writing millions of records fails halfway through, you’re left with a corrupted, unusable table.
- Concurrent operations are a nightmare. Trying to read from a dataset while another process is writing to it can lead to errors or inconsistent, phantom results.
- Updates are inefficient. To change a single record, you often have to rewrite entire partitions or files, a slow and expensive process.
- Data quality is a gamble. With no schema enforcement, a rogue pipeline could write strings into a date column, silently corrupting your data and breaking downstream reports.
The Solution: Adding a Brain to Your Storage
Delta Lake solves these problems by wrapping your data files (stored in the efficient Parquet format) with a crucial component: a transaction log. This log is an ordered record of every single change ever made to your table. It’s the single source of truth that brings ACID (Atomicity, Consistency, Isolation, Durability) transactions to your data lake.
When an UPDATE command is run, Delta Lake doesn’t change the original data file. Instead, it writes a new file with the updated data and atomically adds a commit to the log, marking the old file as “no longer valid” and the new one as “active.”
This simple but powerful mechanism unlocks features once exclusive to warehouses:
- ACID Transactions: Jobs either complete fully or not at all. Concurrent reads and writes don’t interfere with each other. Your data is always in a consistent state.
- Time Travel: Since old versions of data files are preserved, you can query your table as it existed at any point in time. This is a game-changer for debugging, auditing, and rolling back bad data loads.
- Schema Enforcement & Evolution: Protect data quality by preventing writes that don’t match the table’s schema, while still allowing for deliberate schema changes over time.
- Unified Batch and Streaming: A Delta table can be both a sink for a real-time data stream and a source for a large-scale batch job, dramatically simplifying your architecture.
Delta Lake in Microsoft Fabric: A Practical Example
Nowhere is the importance of Delta Lake more evident than in Microsoft Fabric. In Fabric, Delta is not an option; it is the default, foundational format for its unified storage layer, OneLake.
This “one copy” approach eliminates data silos and costly data duplication. Let’s walk through a common workflow.
Step 1: Ingest Raw Data (Bronze Layer)
A data engineer uses a Fabric Notebook to ingest raw customer CSV data into a “Bronze” table. Fabric automatically uses the Delta Lake format.
# Ingest raw CSV data from a sourcedf_raw = spark.read.format("csv").option("header", "true").load("Files/raw/customers.csv")
# Save it as a Delta table in the Lakehousedf_raw.write.mode("overwrite").saveAsTable("Customers_Bronze")The data is now reliably stored in OneLake, but it’s still raw.
Step 2: Clean and Transform (Silver Layer)
Next, the engineer reads from the Bronze Delta table, cleans it, and saves it as a new, business-ready “Silver” table.
# Read from the Bronze Delta tabledf_bronze = spark.table("Customers_Bronze")
# Perform transformations (fix data types, rename columns)from pyspark.sql.functions import col, to_date
df_silver = df_bronze.withColumn("RegistrationDate", to_date(col("reg_date"), "MM-dd-yyyy")) \ .withColumnRenamed("id", "CustomerID") \ .drop("reg_date")
# Save the cleaned data as a new Silver Delta tabledf_silver.write.mode("overwrite").saveAsTable("Customers_Silver")Step 3: Unify the Experience
This Customers_Silver Delta table is the single source of truth. Without moving or copying it, it’s instantly available to different users across Fabric:
- The Data Analyst: Opens the Lakehouse’s SQL Analytics Endpoint and immediately queries the table with standard T-SQL.
SELECT Country, COUNT(CustomerID) AS CustomerCountFROM dbo.Customers_SilverGROUP BY Country;
- The BI Developer: Opens Power BI, connects to the Fabric semantic model, and uses DirectLake mode on the
Customers_Silvertable. This mode queries the Delta files directly, providing blazing-fast performance without importing and duplicating the data.
This seamless interoperability is only possible because Delta Lake provides a reliable, open, and transactional foundation that all the different Fabric engines can understand and trust.
Why Not Just Use a Database?
For many use cases, traditional databases and warehouses remain the right choice, especially for application backends (OLTP) or serving highly curated data where performance is paramount.
You choose the Lakehouse architecture powered by Delta Lake when:
- Scale is massive and cost is a factor. Storing petabytes of data in a warehouse is often financially unfeasible.
- You need a single source of truth for all data types—raw, semi-structured, and processed—without vendor lock-in.
- Flexibility is key. You want to use the best compute engine for the job (Spark, T-SQL, etc.) on a single copy of your data.
Delta Lake isn’t just a file format. It’s the technology that bridges the chasm between data lakes and data warehouses, creating a robust, reliable, and unified foundation for the future of data platforms.
Any Questions?
Contact me on any of my communication channels: