#43 A Comprehensive Guide to Data Vault 2.0: The Agile Data Warehouse
/ 8 min read
Updated:TL;DR
Data Vault 2.0 is a modern way to build a data warehouse that is super flexible and won’t break when business needs or data sources change.
Instead of big, rigid tables, it splits data into three simple parts:
- Hubs: The core business concepts (the “nouns,” like
CustomerIDorProductSKU). These are stable and just hold the business keys. - Links: The relationships between Hubs (the “verbs,” like a customer buys a product).
- Satellites: The descriptive details (the “adjectives,” like a customer’s name or a product’s price). They track all history by adding new rows, never updating, which makes the data fully auditable.
The result is a scalable, adaptable core. For users to actually run reports, you build familiar, easy-to-use Information Marts (like star schemas) on top of this solid foundation.
A Comprehensive Guide to Data Vault 2.0: The Agile Data Warehouse
In the world of data warehousing, the core challenge has always been to build a system that is both a stable, single source of truth and flexible enough to adapt to ever-changing business requirements. Traditional methodologies like those from Inmon (3NF) and Kimball (Star Schema) have been the bedrock of analytics for decades, but they can struggle with the speed and scale of modern data.
This is where Data Vault 2.0 comes in. It’s not just a modeling technique; it’s a complete methodology designed to create an agile, scalable, and highly auditable enterprise data warehouse. This article provides a deep dive into the what, why, and how of Data Vault 2.0, from its core principles to practical implementation in a modern platform like Microsoft Fabric.
Step 1: The “Why” - Problems Data Vault Solves
To understand the genius of Data Vault, we must first appreciate the limitations of the traditional approaches:
- Kimball (Dimensional Modeling): Famous for the star schema, this approach is optimized for fast, easy-to-understand queries. However, it is highly dependent on predefined business processes. When a business process changes, the fact tables and dimensions often require significant, costly redesign.
- Inmon (Normalized Form - 3NF): This “hub-and-spoke” model excels at creating a highly integrated, non-redundant central repository. Its downside is complexity. The sheer number of tables and joins required to get a business-centric view can be daunting for both ETL developers and end-users.
Data Vault 2.0 was created by Dan Linstedt to be a hybrid, taking the best of both worlds. It focuses on modeling the business itself—its core entities and relationships—rather than a specific business process. This creates a resilient foundation that doesn’t break when processes change.
Step 2: The Core Principles of the Methodology
Data Vault 2.0 is more than just tables; it’s a system of architecture, methodology, and modeling.
- Methodology: It embraces agile, data-driven development. New data sources can be added incrementally without disrupting the existing structure, allowing for faster delivery of value.
- Architecture: It defines distinct layers. Data flows from a Staging Area into the Raw Data Vault, which is the historical, unaltered source of truth. From there, data can be cleansed and transformed into a Business Vault to apply enterprise-wide rules. Finally, user-facing Information Marts (often star schemas) are built on top for reporting and analytics.
- Model: This is the heart of the system, comprised of three fundamental building blocks.
Step 3: The Building Blocks - Hubs, Links, and Satellites
The Data Vault model’s flexibility comes from its separation of business keys, relationships, and descriptive attributes.
1. Hubs (The Business Anchors)
Hubs represent core business entities. They contain a distinct list of the natural business keys that uniquely identify each entity.
- Purpose: To establish a single, integrated list of business concepts (e.g., customers, products, employees).
- Key Columns:
HubHashKey: A generated primary key based on the business key.BusinessKey: The natural key from the source system (e.g., CustomerID, ProductSKU).LoadDate: The timestamp when the record was first loaded.RecordSource: The system from which the record originated.
2. Links (The Relationships)
Links establish the relationships or transactions between Hubs. They are essentially many-to-many join tables that create the “web” of the business.
- Purpose: To capture a unique association between two or more business entities.
- Key Columns:
LinkHashKey: A generated primary key based on the combined business keys of the connected Hubs.HubHashKey_1: The foreign key to the first Hub.HubHashKey_2: The foreign key to the second Hub.LoadDate: The timestamp when the relationship was first recorded.RecordSource: The originating system.
3. Satellites (The Context)
Satellites store the descriptive, contextual, and historical attributes for a Hub or a Link. This is where all the rich detail lives.
- Purpose: To store all descriptive data and track changes over time. Data in a Satellite is never updated or deleted; new rows are inserted, providing a complete audit trail.
- Key Columns:
ParentHashKey: The foreign key to the parent Hub or Link.LoadDate: The timestamp when this version of the attributes was loaded. This is part of the primary key to track history.RecordSource: The originating system.Descriptive_Attributes...: All other columns describing the parent (e.g., CustomerName, Address, OrderStatus, UnitPrice).
Step 4: A Practical Example - Modeling an E-commerce System
Let’s apply these concepts to a simple order management scenario.
-
Identify Business Entities (Hubs):
Customer(identified byCustomerID)Product(identified byProductSKU)Order(identified byOrderID)
-
Identify Relationships (Links):
- An order is placed by one customer (
Link_Customer_Order). - An order contains one or more products (
Link_Order_Product).
- An order is placed by one customer (
-
Add Descriptive Attributes (Satellites):
- Customer details (Name, Email) ->
Sat_Customer_Details - Product details (Name, Price) ->
Sat_Product_Details - Order details (OrderDate, Status) ->
Sat_Order_Details - Line item details (Quantity) ->
Sat_Order_Product_Details(a Satellite on a Link)
- Customer details (Name, Email) ->
The resulting model would look something like this:
+-------------------------+ | Sat_Customer_Details | +-------------------------+ ^ |+------------------+ +-----------------------+ +---------------+| Hub_Customer |<--->| Link_Customer_Order |<--->| Hub_Order |+------------------+ +-----------------------+ +---------------+ ^ ^ | | +-----------------------+ +---------------------+ | Link_Order_Product |<--->| Hub_Product | +-----------------------+ +---------------------+ ^ ^ ^ | | | +-------------------------+ +-----------------------+ | Sat_Order_Product_Details | | Sat_Product_Details | +-------------------------+ +-----------------------+ +-------------------+ | Sat_Order_Details | +-------------------+Step 5: The Engine Room - Generating Hash Keys in Microsoft Fabric
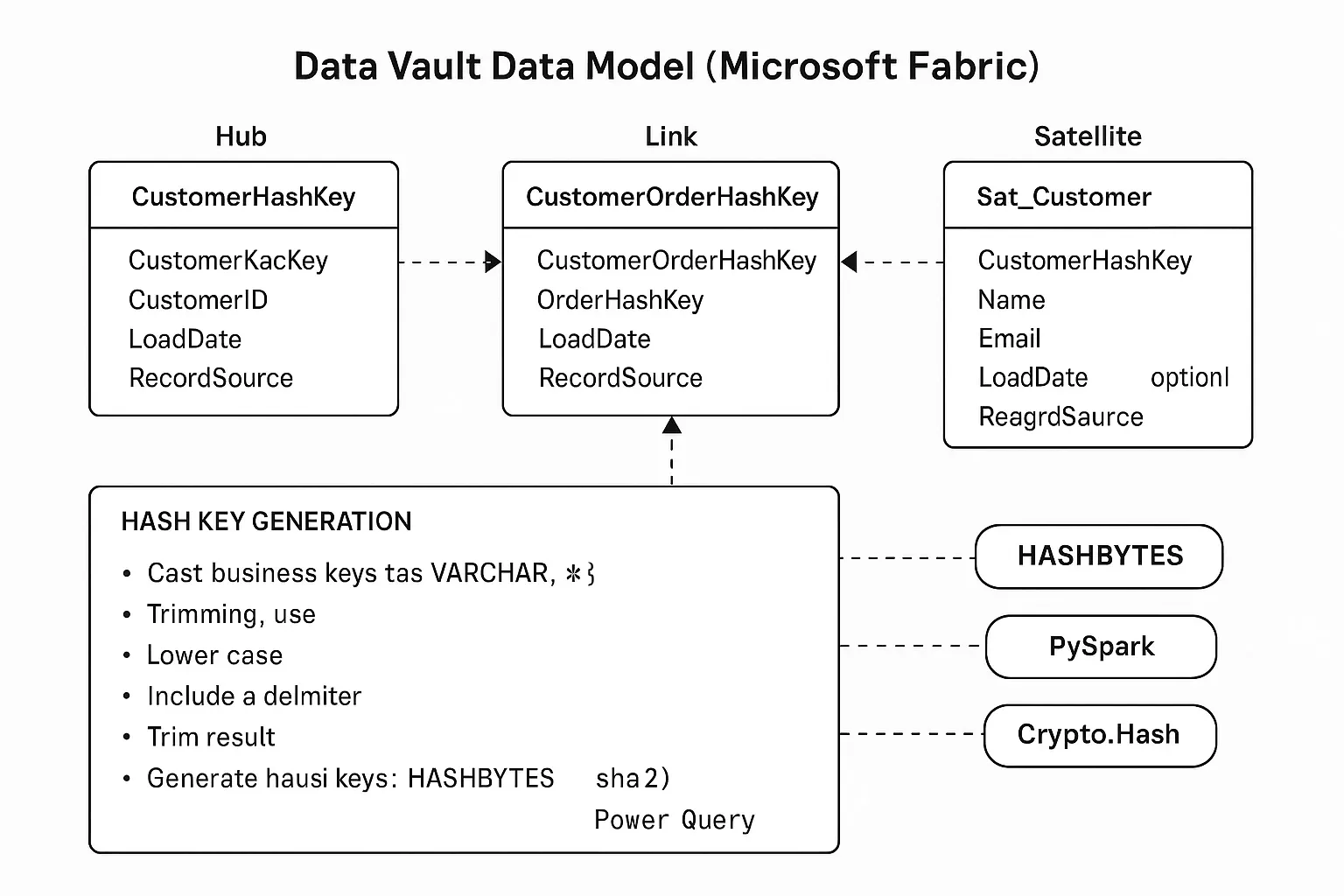
Hash keys are the engine of Data Vault 2.0. They are generated during the data ingestion process by applying a cryptographic hash function (like MD5 or SHA2_256) to the business key(s).
Why use generated hash keys?
- Parallelism: Different load processes can generate the same key for the same business entity without needing to coordinate, enabling massive parallel loading.
- Decoupling: A process loading a Satellite doesn’t need to look up a surrogate key in the Hub. It can calculate the key independently, simplifying ETL logic.
- Automatic Integration: If two source systems provide data for
CustomerID = 'ABC-123', they will both generate the exact sameCustomerHashKey, automatically integrating the data.
Here’s how to implement this in Microsoft Fabric:
Using T-SQL in a Warehouse
The HASHBYTES function is ideal. Best practice is to standardize the input to ensure consistency.
-- Generate a Hub Hash KeySELECT HASHBYTES( 'SHA2_256', UPPER(TRIM(CAST(CustomerID AS VARCHAR(255)))) ) AS CustomerHashKey, CustomerID, GETUTCDATE() AS LoadDate, 'SourceSystem1' AS RecordSourceFROM Staging.Customers;
-- Generate a Link Hash Key by concatenating business keysSELECT HASHBYTES( 'SHA2_256', CONCAT( UPPER(TRIM(CAST(CustomerID AS VARCHAR(255)))), '|', UPPER(TRIM(CAST(OrderID AS VARCHAR(255)))) ) ) AS CustomerOrderHashKeyFROM Staging.Orders;Using PySpark in a Notebook
Spark’s built-in functions are perfect for large-scale transformations.
from pyspark.sql.functions import sha2, upper, trim, col, concat_ws
# For a Hubdf_hub = df_staging.withColumn( "CustomerHashKey", sha2(upper(trim(col("CustomerID"))), 256))
# For a Linkdf_link = df_staging.withColumn( "CustomerOrderHashKey", sha2( concat_ws("|", upper(trim(col("CustomerID"))), upper(trim(col("OrderID")))), 256 ))Step 6: Getting Data Out - The Information Mart
The Raw Data Vault, with its many tables and joins, is not designed for direct querying by business analysts. Its purpose is to be an auditable, integrated repository.
To serve analytics, you build Information Marts on top of the Vault. These are typically Kimball-style star schemas (fact and dimension tables) that are optimized for reporting. You create views or materialized tables that join the necessary Hubs, Links, and Satellites to produce clean, user-friendly dimensions and facts.
This architecture gives you the best of both worlds: a resilient, integrated core (the Vault) and a high-performance, easy-to-use presentation layer (the Marts).
Step 7: The Balanced View - Pros and Cons
Advantages:
- Agility & Flexibility: New data sources can be added with minimal disruption.
- Auditability: The model provides a complete, built-in history of every data point.
- Scalability: The design is optimized for parallel loading and can handle petabyte-scale environments.
- Fault Tolerance: Bad data in one Satellite doesn’t corrupt the entire model or stop other data from loading.
Disadvantages:
- Complexity: The model results in a high number of tables, which means more joins are required to produce a business view. This is why Information Marts are essential.
- Learning Curve: The methodology requires a shift in thinking for developers accustomed to traditional modeling.
- Initial Overhead: For very simple projects with few data sources, Data Vault can feel like over-engineering.
Conclusion
Data Vault 2.0 is a powerful, modern approach to building an enterprise data warehouse that can withstand the tests of time and change. By separating the stable business keys from their ever-changing descriptive context, it provides a flexible and scalable foundation. While it introduces a new way of thinking, its ability to deliver an agile, auditable, and resilient data platform makes it an indispensable methodology for any organization serious about its data architecture.
Any Questions?
Contact me on any of my communication channels: